Language Resource
In our lab, we also creating language resources by using and combining cutting-edge technologies. Our projects are listed below.
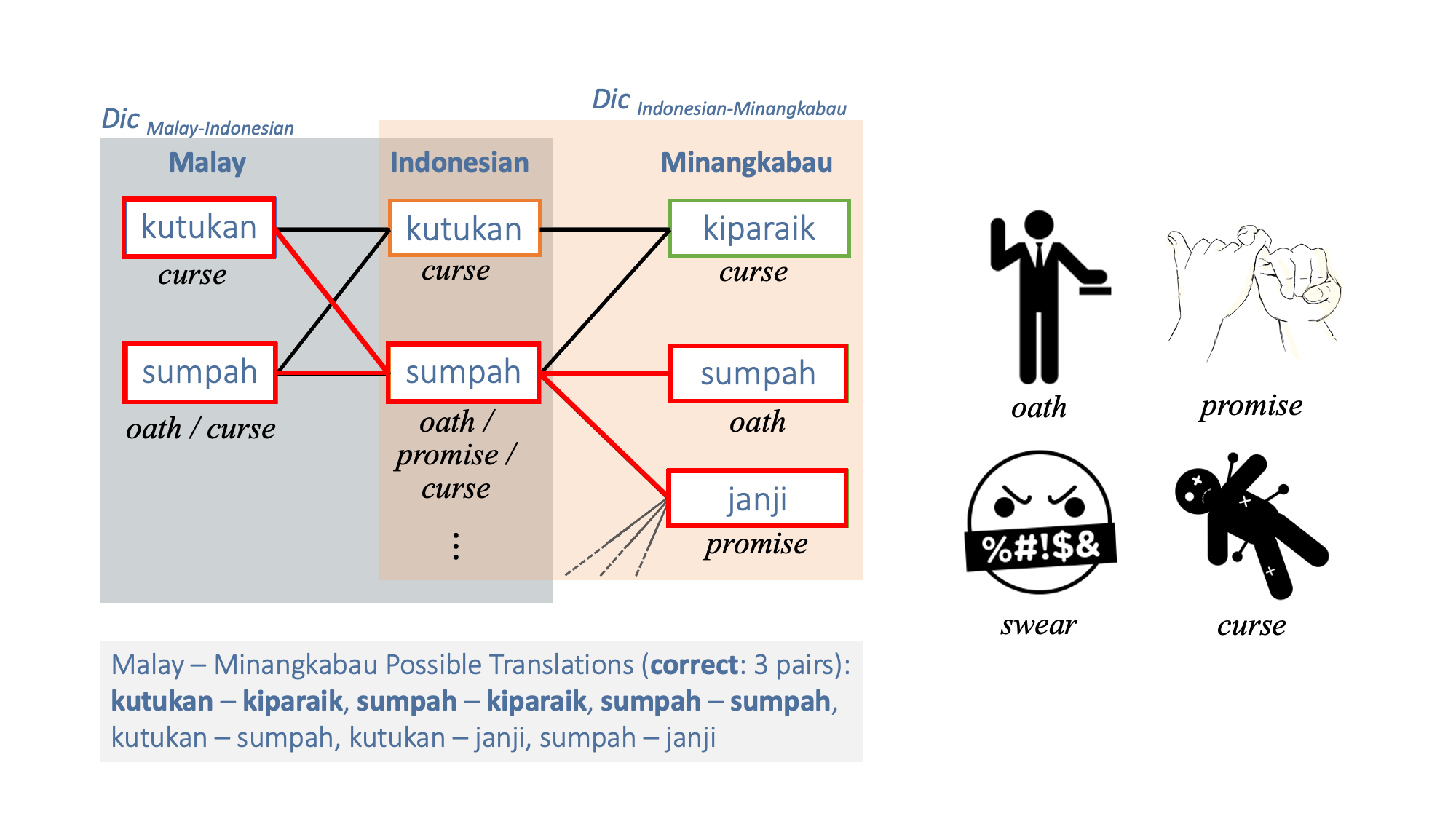
Pivot-based Bilingual Dictionary Induction for Low Resource Languages
Many Indonesian languages belong to the Austronesian language family, which are very similar languages with the same ancestral language. To create a new bilingual dictionary between these languages (e.g., Malay and Minangkabau), we generated a network of bilingual dictionaries (Malay-Indonesian bilingual dictionary and Minangkabau-Indonesian bilingual dictionary) with a common pivot language (Indonesian) connecting the bilingual pairs in each dictionary and extracts word pairs 'kutukan (Malay) and kiparaik (Minangkabau)' at both ends as bilingual pairs.However, if the words in the pivot language are polysemic (sumpah (Indonesian) has meanings such as oath, promise, and curse) Word pairs with different meanings 'kutukan (Malay) and janji (Minangkabau)' could be extracted. Therefore, we improve accuracy by extracting only word pairs with symmetric topology.
[Arbi H. Nasution, Yohei Murakami Toru Ishida. A Generalized Constraint Approach to Bilingual Dictionary Induction for Low-Resource Language Families, ACM Transactions on Asian and Low-Resource Language Information Processing, Vol. 17, No. 2, pp. 9:1-29, 2018.,
Arbi H. Nasution, Yohei Murakami Toru Ishida. Plan Optimization to Bilingual Dictionary Induction for Low-Resource Language Families, ACM Transactions on Asian and Low-Resource Language Information Processing, Vol. 20, No. 2, pp. 29:1-28, 2020.]
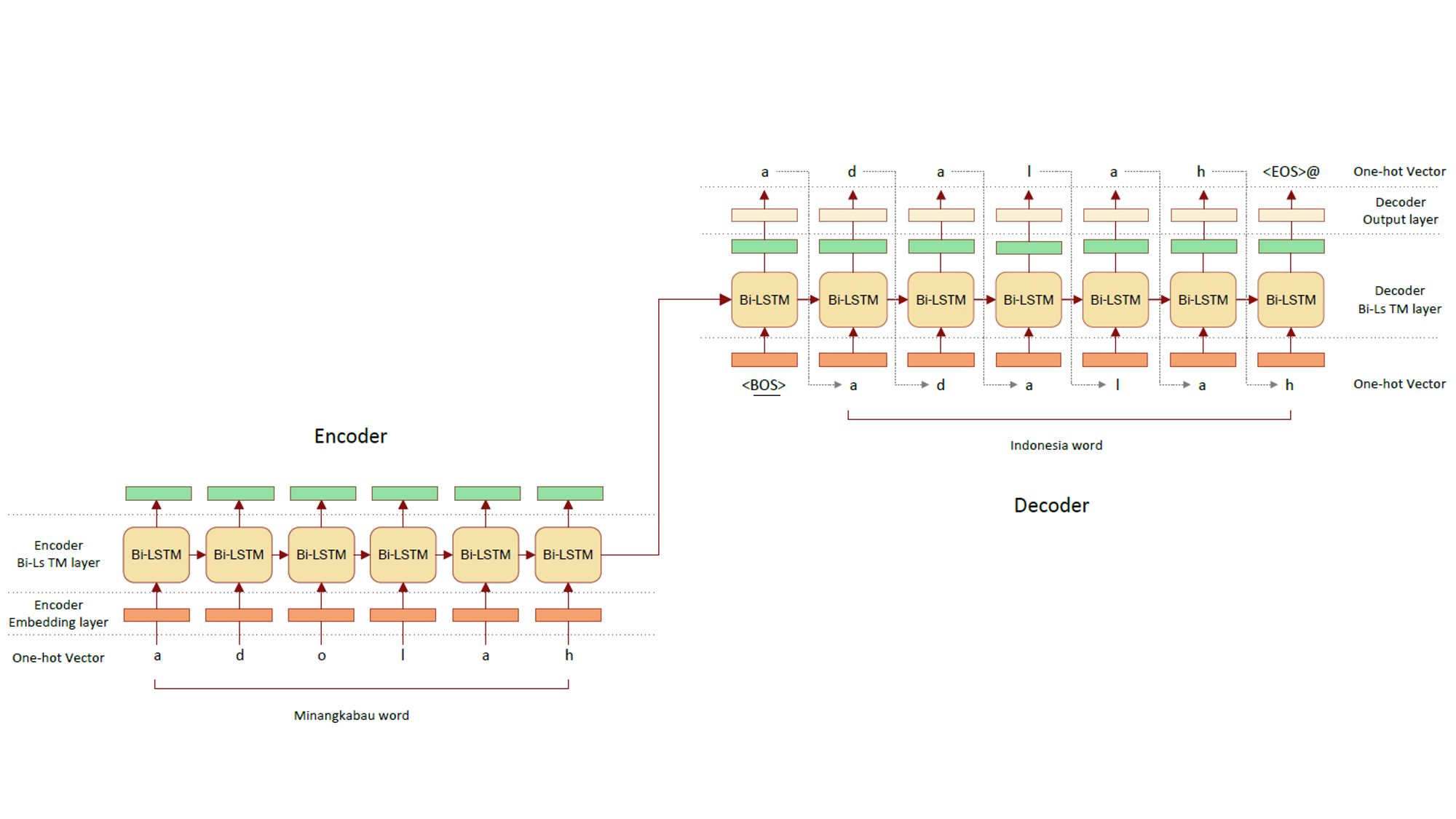
A Neural Network Approach to Bilingual Dictionary for Low Resource Language Families
Many Indonesian languages belonging to the Austronesian language family are very similar. These very similar languages have words called allonyms, which are derived from words in the same ancestral language. Tautologous words are derived language by language from the same word as the pronunciation of each language develops. Pronunciations of allomorphs may show regular changes between languages (e.g., the 'o' at the end of 'a' word changes to 'a'). The goal is to generate a translation by learning this regular change with a neural network and applying this rule to words in one language. We also aim to contribute to comparative linguistics by generating hypotheses about derivational relations between languages based on the similarity of the acquired rules.
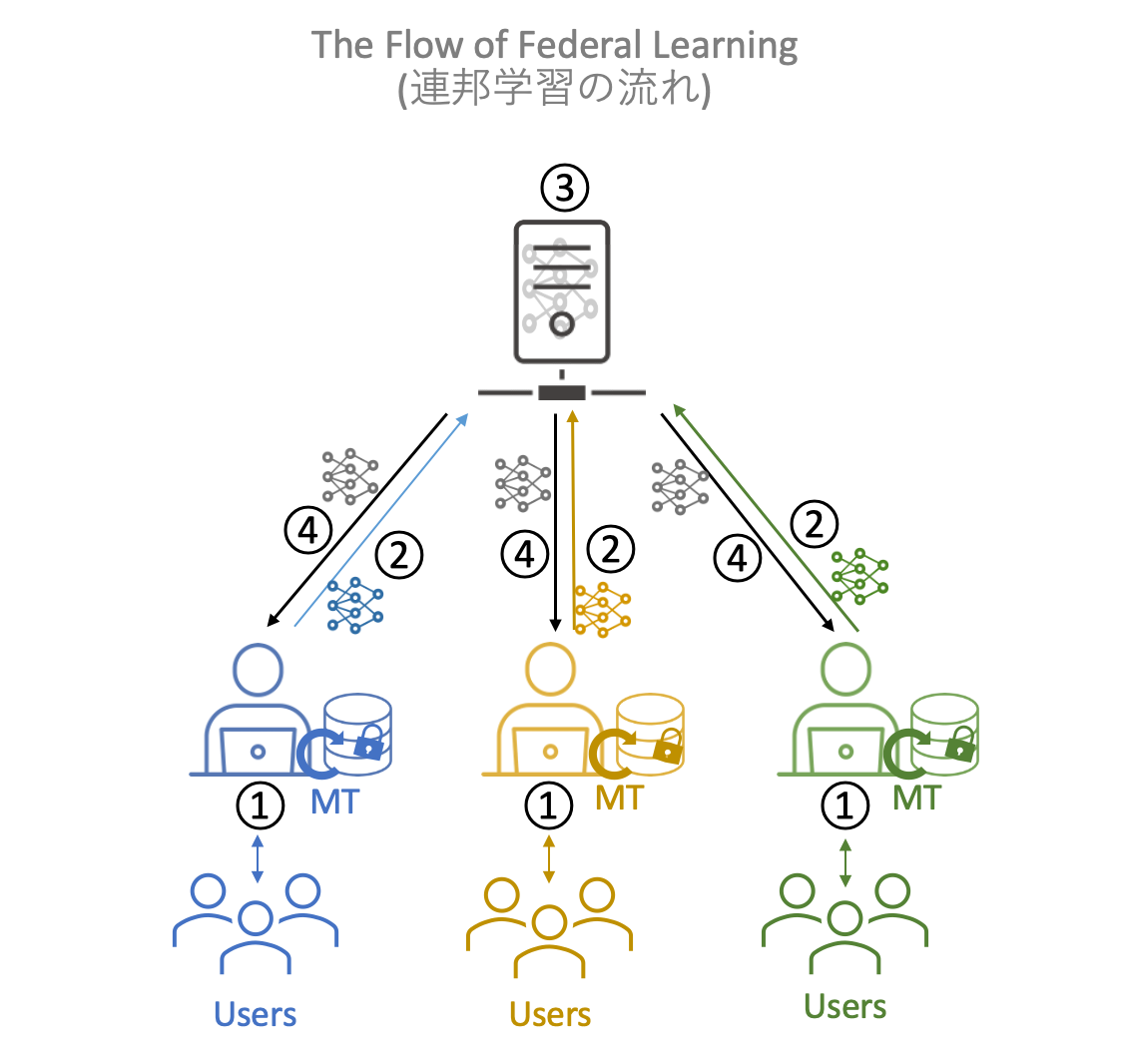
Decentralized Neural Machine Translation
Building a highly accurate neural machine translation requires a large amount of high-quality bilingual data. However, the construction of such bilingual data incurs significant costs, making it difficult for a single organization to construct such data.In addition, the collection of bilingual data created by different organizations is also hampered by copyright issues, making it difficult to consolidate.Therefore, rather than consolidating the bilingual data in one place for learning, models can be generated by learning the bilingual data under each data owner and then By using federal learning, in which the models are federally linked, we aim to build a decentralized neural machine translation system.
Presentation: 北川勘太朗, 張禹王, 村上陽平. マルチエージェント強化学習を用いたニューラル機械翻訳の連携, 情報処理通信学会総合大会, 2024
Neural Machine Translation Bias Analysis
With the English language becoming Lingua Franca, there are now diversed styles of English language that are caused by non-native speakers while the society accepts these diversed language. Neural machine translation, on the other hand, uses a large bilingual data set to train a single model and Machine translation generates only one style of English language. If the training data is biased toward the English of native English speakers, the current variety of English is lost and English may become the only English spoken by native English speakers. As a result, English expressed from a different perspective from that of non-native English speakers will be communicated to others. In this study, we call this case machine translation bias. This trend is expected to accelerate in the future as the use of machine translation progresses and society is flooded with English based on machine translation-generated translations. Therefore, this study will compare and analyze English written by non-native English speakers and English generated by machine translation in order to determine whether such machine translation bias exists or not, and if so, what kind of bias is there